In this activity, you will build an interactive web application for classifying Iris flower species using Streamlit and a Random Forest Classifier algorithm. This practical is a hands-on demonstration of combining machine learning and web application development to create a user-friendly tool for predictive analysis.
Streamlit is an open-source Python framework for data scientists and AI/ML engineers to deliver dynamic data apps with only a few lines of code. Build and deploy powerful data apps in minutes.
Overview
The Iris dataset is a well-known dataset in machine learning, containing information about:
- Sepal length
- Sepal width
- Petal length
- Petal width
- Target species (Setosa, Versicolor, Virginica)
- You will use this dataset to train a machine learning model.
- You will train a Random Forest Classifier using the Iris dataset.
- The model learns the relationship between the input features (sepal and petal dimensions) and the target species.
Follow the below steps to perform this activity
- Create a requirements.txt file and add the library name that will be used.
numpy
pandas
streamlit
scikit-lear
Now in the terminal run the below command to install the libraries.
pip install -r requirements.txt
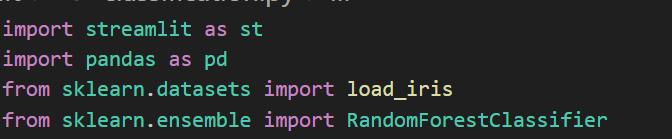
2. Now create the main python file and start by importing the libraries.
3. Load and Preparing the data
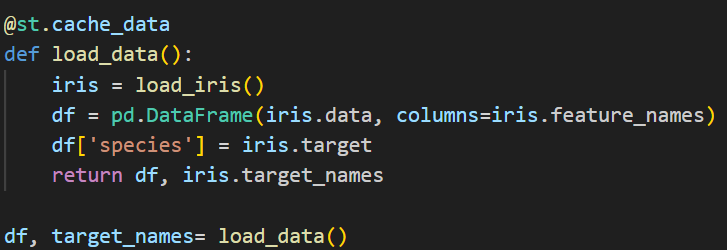
Used the @st.cache_data decorator which is used to cache the output of the function, ensuring that the function runs only once for a given set of inputs during a session. When the function is called again with the same inputs, the cached result is used instead of recomputing the output.
The load_iris() is used to load the Iris dataset into memory. This dataset contains feature data (dimensions of iris flowers) and their corresponding species labels.
The function returns df : The Pandas DataFrame containing the features and species and iris.target_names and a list of species names ([“setosa”, “versicolor”, “virginica”]), used later for prediction output.
The iris.data array is converted into a Pandas DataFrame which creates a table with column names for the features (e.g., “sepal length (cm)”)
The species labels from iris.target are added to the DataFrame as a new column named ‘species’ which is the target coloumn.
3. Training the Random Forest classifier

RandomForestClassifier is a machine learning algorithm from the sklearn.ensemble module.
It initialises the classifier with default parameters and creates a forest of decision trees for classification.
The fit(X,y) method trains the model on the given dataset.
y : The target labels (output values).
X: The feature data (input values).
So it selects all rows and all columns except the last column (‘species’). The resulting DataFrame contains the feature data, which are the measurements of the iris flowers (sepal length, sepal width, petal length, petal width). This is the input data, or X.
The ‘species’ column contains the species of each iris flower in numerical form and this is the target variable y what the model will try to predict based on the input features X.
4. Creating a Sidebar for user Inputs

st.sidebar.title: Adds a title to the sidebar for better organisation.
st.sidebar.slider:
- Creates sliders for user inputs.
- Each slider corresponds to one feature (sepal/petal length/width).
- The range of the slider is determined by the minimum and maximum values of each feature in the dataset.
Users adjust sliders to provide feature values and these values act as inputs for the prediction model.
5. Creating Input data for Prediction

Here, it created a list of lists representing the input features of a single flower sample. This data will be fed into the trained model for making predictions.
6. Making the Predictions

The model.predict(input_data) uses the trained Random Forest model to predict the species based on the input data and returns a numeric label (0,1 or 2)
target_names[prediction[0]] maps the numeric label to the corresponding species name.
7. Displaying the Prediction

st.write:
- Displays the prediction on the web app.
- Outputs the predicted species based on user input.
Final code
import streamlit as st
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
@st.cache_data
def load_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
return df, iris.target_names
df, target_names= load_data()
model=RandomForestClassifier()
model.fit(df.iloc[:, :-1], df['species'])
st.sidebar.title("Input Features")
sepal_length = st.sidebar.slider("Sepal length", float(df['sepal length (cm)'].min()),float(df['sepal length (cm)'].max()))
sepal_width = st.sidebar.slider("Sepal width", float(df['sepal width (cm)'].min()),float(df['sepal width (cm)'].max()))
petal_length = st.sidebar.slider("Petal length", float(df['petal length (cm)'].min()),float(df['petal length (cm)'].max()))
petal_width = st.sidebar.slider("Petal width", float(df['petal width (cm)'].min()),float(df['petal width (cm)'].max()))
input_data = [[sepal_length, sepal_width, petal_length, petal_width]]
## prediction
prediction = model.predict(input_data)
predicted_species = target_names[prediction[0]]
st.write("prediction")
st.write(f"The predicted species is: {predicted_species}")Output
For running this streamlit application execute the below command:
streamlit run Let’s see the code in action
with this, you have built an Iris Flower classification model using Streamlit.