In this article, you will learn about the lemmatization and stop-words which are a part of a text preprocessing.
Lemmatization is the process of reducing words to their base or dictionary form, known as the lemma.
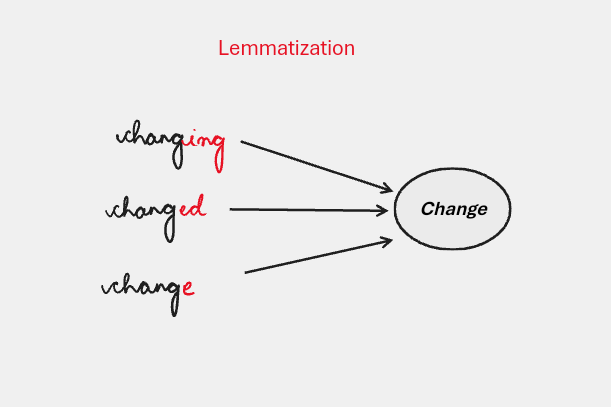
Implementation of Lemmatization
- Start by importing the Libraries.
import nltk
from nltk.stem import WordNetLemmatizer
The WordNetLemmatizer is part of the Natural Language Toolkit (NLTK) library and is used for Lemmatization. It uses the WordNet Lexical Database to find the base form of a word.
2. Create an Instance of the WordNetLemmatizer class.
lemmatizer=WordNetLemmatizer()
3. Download the wordNet which is a lexical database of english to perform Lemmatization.
nltk.download('wordnet')
4. The lemmatize() accepts two parameters word and pos(optional and by default pos=’n’).
word is of type string which you want to lemmatize and The Part of Speech (POS) tag for the word helps the lemmatizer understand the grammatical role of the word to provide an accurate base form (lemma).
'n' → Noun (default)'v' → Verb'a' → Adjective'r' → Adverb
lemmatizer.lemmatize("going",pos='v')
#Output--go
5. Applying Lemmatization to a list of words.
words=["eating","eats","eaten","writing","writes","programming","programs","history","finally","finalized"]
for word in words:
print(word+"-"+lemmatizer.lemmatize(word,pos='v'))
output

Both Lemmatization and Stemming are used for the Text normalization technique but the difference is that lemmatization is slower due to its more complex processing and provides more accurate result.
Now lets look into how to remove Stopwords which are frequently filtered out to increase the text analysis efficiency. Certain words, like “the,” “and,” and “is,” words do not contribute much to the meaning of a sentence and are often removed to focus on the more important words (keywords) for analysis.
Implementation of Stop words
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Download required NLTK resources
nltk.download('stopwords')
nltk.download('punkt')
# Example paragraph
paragraph = """Natural Language Processing (NLP) is a fascinating field of artificial intelligence.
It enables computers to understand, interpret, and respond to human language in a valuable way."""
# Get English stop words
stop_words = set(stopwords.words('english'))
# Tokenize the paragraph into words
words = word_tokenize(paragraph)
# Filter out the stop words
filtered_words = [word for word in words if word.lower() not in stop_words]
# Print the original and filtered text
print("Original Paragraph:\n", paragraph)
print("\nTokenized Words:\n", words)
print("\nFiltered Words (without stop words):\n", filtered_words)
Output

Summary
In this article, you explored the lemmatization and stop words topic along with their implementation.
Similar Topics
Stemming Techniques using NLTK Library
Exploring Different Tokenization Techniques in NLP using NLTK Library